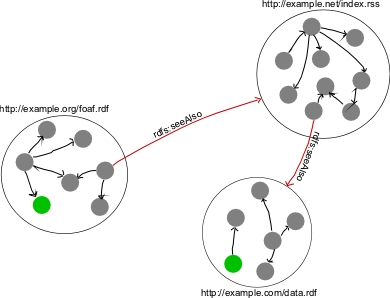
Figure 1. Three RDF files, connected via
rdfs:seeAlso
http://seco.semanticweb.org/
Andreas Harth
DERI at NUI Galway and USC Information Sciences Institute
aharth@isi.edu
The Semantic Web has motivated many communities to provide data in a machine-readable format. However, the available data has not been utilized to far to the extent possible. The data, which has been created by a large number of people, is dispersed across the Web. Creating the data without central coordination results in RDF of varying quality and makes it obligatory to cleanse the collected data before integration. The SECO system presented in this paper harvests RDF files from the Web and consolidates the different data sets into a coherent representation aligned along an internal schema. SECO provides interfaces for humans to browse and for software agents to query the data repository. In this paper, we describe the characteristics of RDF data available online, the architecture and implementation of the SECO application, and discuss some of the experienced gained while collecting and integrating RDF on the Web.
The Semantic Web has motivated grassroots efforts to develop and publish ontology specifications and various other people on the Web provided hand-crafted instance data in RDF for these ontologies. Examples include FOAF (Friend Of A Friend) [Brickley and Miller] that is used in the Semantic Web community to describe people and their relationships, and RDF Site Summary 1.0 [RSS-DEV Working Group] that is used in the weblog community to syndicate news items. Both formats are encoded in RDF, are based on relatively compact ontologies, and enjoy wide community support. The distributed RDF files on the Web, connected by links, represent a web of data that has been built by a collaborative effort of thousands of people.
So far, the RDF data on the Web has been utilized inadequately, mostly because it is difficult to locate and combine the files and query the resulting information since the RDF files are dispersed across several thousand web sites. News aggregators such as Google News [Google News] scrape the news items out of HTML pages but are not using RSS feeds, RSS aggregators such as AmphetaDesk [AmphetaDesk] are client applications, and FOAF aggregators such as PeopleAggregator [PeopleAggregator] solely cover a fraction of all FOAF data available. Most importantly, the aggregators lack a query interface for software agents to access the integrated data.
SECO, the application presented in this paper, acts as a mediator [Wiederhold 1992] that aggregates arbitrary RDF files from the Web and constructs a user interface in HTML from the integrated data sets using a three-stage approach. Software agents can query the RDF data set using a remote query interface over HTTP. In the following, we describe the qualities of the data currently available on the Semantic Web, show the architecture of SECO, explain its implementation, and conclude with discussion and future work.
To mimic of the structure of the existing hypertext web - documents and links between documents - the rdfs:seeAlso property is used, especially in FOAF datasets.
The usage of the rdfs:seeAlso link to connect RDF documents makes it possible to use an RDF crawler for traversing the web of RDF files.
Figure 1 illustrates three RDF files (large circles) that are connected via rdfs:seeAlso properties.
The files contain statements consisting of resources (solid circles) and properties (arrows).
Resources with the same URI in different files, depicted in green, provide a way to connect the various RDF data sets.
rdfs:seeAlso
SECO consists of a crawler, wrappers, a transformer, a user interface, a remote query interface, and a data repository as depicted in Figure 2. The data repository consists of four different sets of RDF data: the MetaModel contains metadata about the harvested files, the SourceModel contains the original RDF triples from the RDF files on the Web, the TargetModel contains cleaned data, and the UsageModel contains site usage data from the user interface. The data in the MetaModel, the UsageModel, and the TargetModel is specified by ontologies, while the data in the SourceModel can be of any schema and is therefore not specified. The crawler collects data from RDF files and from legacy data sources that are converted into RDF by wrappers and stores the incoming data in the SourceModel. The transformer takes the data from the SourceModel, cleans it, and stores the results in the TargetModel, that is accessed by the user interface to produce HTML and by the remote query interface to answer queries.
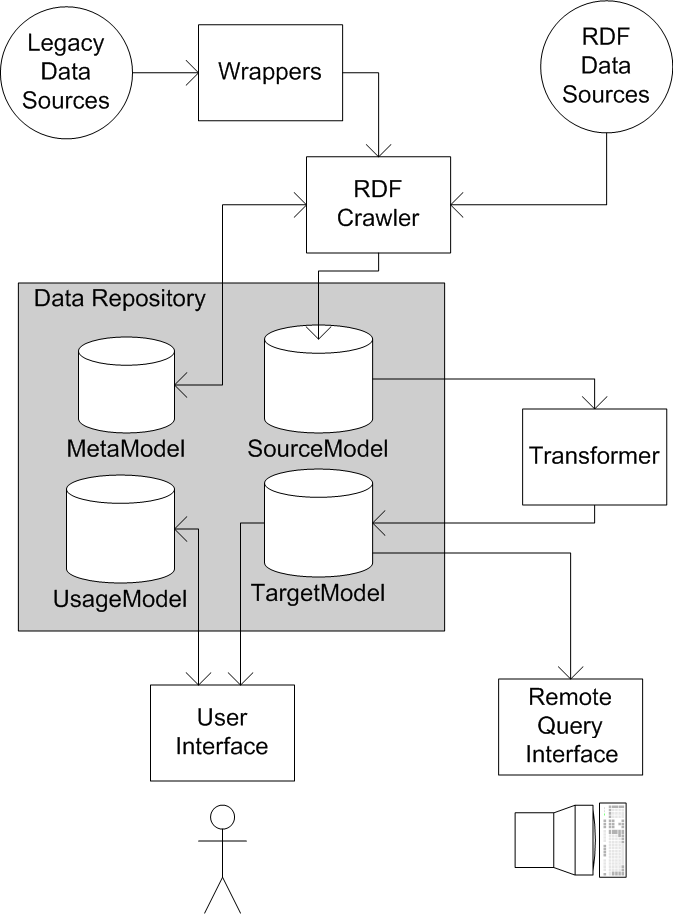
The RDF crawler traverses the web of data by following rdfs:seeAlso links.
By relying on the links inside RDF files, the crawler can visit a large portion of the Semantic Web without the need to find the location of RDF files from sources that cannot be easily processed with the RDF toolkit.
The locations of the wrappers, which are used by the crawler to access legacy data sources, have to be provided manually.
A basic set of customized wrappers to convert the content of legacy data sources into RDF is part of SECO. The wrapper provided are accessible via HTTP and return an RDF representation of the data from the underlying datastore, that can be included into the data repository by the crawler in the same way as native RDF data. Table 1 summarizes the types, original formats and original protocols of the legacy data sources that can be included into the crawling process.
| Type | Format | Protocol |
|---|---|---|
| RfC822 | IMAP4 | |
| Google API | XML | SOAP Web Service |
| RSS 0.92 and 2.0 | XML | HTTP |
| Web pages | HTML | HTTP |
Metadata related to the web crawling process, such as the date of the last visit of a file, the HTTP return code, or a copy of the robots.txt file from sites, is stored in the MetaModel. The crawling is carried out continuously. Properties within the RDF files can determine the update frequency of the files, otherwise a default value is assumed. The crawler gathers RDF files from the Web, validates for correct XML and RDF syntax, and then stores the RDF statements of the files in the SourceModel using the RDF reification mechanism to track their provenance.
This component transforms statements from the SourceModel to the TargetModel by conducting the following steps:
rdf:type statements are omitted.
xml:lang information based on statements in the original RDF file to provide multi-language support.
foaf:mbox_sha1sum property, which has been computed in the previous step if was not already present in the original RDF file.
In FOAF, a person is uniquely identified based on the SHA1 hash sum [FIPS 180-1 1995] over the foaf:mbox property to hide the real email address from spammers.
The remote query interface in SECO is an implementation of the RDF Net API [Seaborne 2002] and allows software agents to issue queries in the RDF Query Language (RDQL) [Miller et al. 2002] over HTTP.
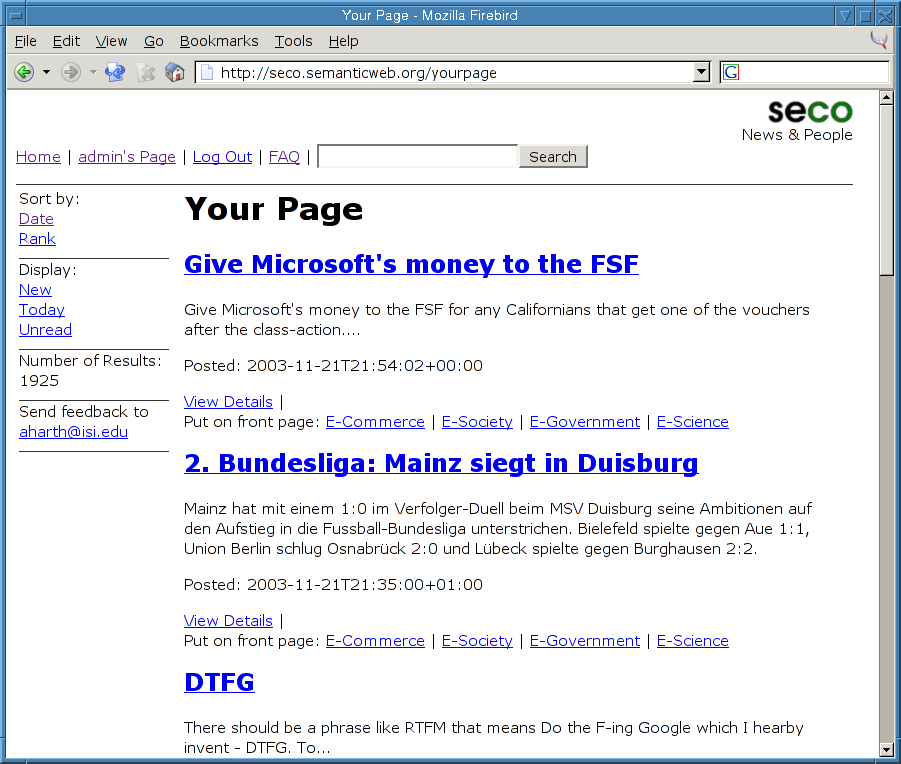
The user interface consists of HTML pages that are generated from the TargetModel. Once logged in, both users and editors can browse, rate, and sort the news items, while editors are also able to select their choice of news items for the publicly accessible front page. Users rating news items, the admin selecting a news item for the front page, and other actions performed through the user interface are logged into the UsageModel. The screenshot in Figure 3 shows the editor's page with three news items, where one item originated from slashdot, one from a German public television news show, and another one from a personal blog. Users can perform full-text searches on literals in the TargetModel by using the input box in the top center of the page.
The front page, the search results page, the details page, and the personalized page are created in three steps. First, one or more RDQL queries that fetch data for the resulting page in the user interface are executed against the TargetModel. Then, the result of this query is formatted as an XML document. Finally, this XML document is transformed into a presentation oriented HTML page using an XSLT stylesheet that has been customized manually to the output of the query form the previous step. Thus the process of creating HTML from RDF as depicted in Figure 4 comprises of three stages: from content over structure to presentation [Fernandez et al. 1998].
SECO consists of roughly 12000 lines of code and comments embedded in code, excluding libraries and external packages. The components for the crawler and wrappers, the transformer, and the user interface are implemented in 7000 lines of Java code, plus 1500 lines of XSL stylesheets used for creating HTML pages in the user interface. The implementation was test-case driven, resulting in 2500 lines of code for JUnit [JUnit] unit tests. Ontology specifications for the MetaModel, UsageModel, and TargetModel are made up of 1000 lines of RDF.
RDF in SECO is processed and stored using the Jena2 Semantic Web toolkit [McBride 2000], and is made persistent in the MySQL database [MySQL]. Jena2 provides a API implemented in Java for accessing and manipulating RDF for which an active developer community provides code, documentation, and support via a mailing list. Joseki2 [Joseki], an application related to Jena2, is leveraged in SECO for the remote query interface functionality. Joseki is implemented as a set of servlets packaged as a web application.
All components in SECO that serve HTTP - the wrappers, the user interface, and the remote query interface - are implemented as web applications and run inside the Jetty servlet container [Jetty]. In the user interface, every data driven page is produced by one or more queries embedded in a servlet. The queries are customized for the vocabulary used and are expressed in RDQL, except for the cases where queries spread several model or require functionality not available in RDQL such as counting results. In this case, the queries are implemented calling Jena methods from the Java code. Both RDQL queries and Jena methods return XML which is the intermediate format of the servlet.
XSLT stylesheets are applied to the XML produced inside the servlet using the the Xalan2 XSL-T processor [Xalan]. The stylesheets are customized to the queries and pass parameters to the servlet via HTTP Get. The servlet gets the parameters, parses them, and performs the necessary operations on the data repository. Strings displayed in the user interface are language specific and therefore references to the language-specific part of the XSLT stylesheet as described in [Clark 1999].
SECO is built on top of other sub-systems which we gratefully acknowledge: Xalan2, Xerces, Jakarta ORO, ICU4J, util.concurrent, Jena2, Joseki2, Axis, jtidy, Jetty, Google API, MySQL jdbc connector.
We presented the design and the implementation of SECO, an application that collects and aggregates data from the Semantic Web. In SECO, both RDF data and data from legacy data sources using wrappers are collected, the resulting data is cleansed and can be queried by software agents via a remote query server. We presented a three-stage approach to create HTML from RDF using XML as an intermediate representation.
An interesting direction to pursue is to investigate how rules can be used to simplify the transformation process and replace the transformer component implemented in Java with rules [Sintek and Decker 2002] and therefore being able to eliminate the distinction between the SourceModel and TargetModel.
The Semantic Web of today shares a document-centric view with the HTML Web, which is the reason we followed a warehousing approach in our experiment since this is a proven technique applied by Web search engines. However, in future work we plan to incorporate a mediator approach with virtual integration into SECO, similar to the approach employed in the BuildingFinder [Ambite et al. 2003]. The virtual integration approach has better scalability properties that will be increasingly of concern as more ontologies are published and more RDF data is available online.
The software distribution is available at http://seco.semanticweb.org/downloads/ under a BSD-style license.
I'd like to thank the people on the #rdfig IRC channel for comments, suggestions, and code, especially Matt Biddulph for making the hackscutter code available. Thanks to Salim Khan for proofreading, Hongsuda Tangmunarunkit for comments on a draft version of this document, Jose Luis Ambite for valuable insights, and Stefan Decker for critique on numerous versions of this paper.
[Brickley and Miller] Dan Brickley and Libby Miller. "FOAF Vocabulary Specification". Visited 2003-06-18. http://xmlns.com/foaf/0.1/
[RSS-DEV Working Group] RSS-DEV Working Group. "RDF Site Summary (RSS) 1.0". Visited 2003-05-12. http://purl.org/rss/1.0/
[Google News] "Google News". Visted 2003-08-05. http://news.google.com/
[AmphetaDesk] "AmphetaDesk - Syndicated Aggregator". Visited 2003-11-08. http://www.disobey.com/amphetadesk/
[PeopleAggregator] "PeopleAggregator (alpha)". Visited 2003-10-28. http://peopleaggregator.com/
[Wiederhold 1992] Gio Wiederhold. "Mediators in the Architecture of Future Information Systems". IEEE Computer, March 1992, pages 38-49. 1992.
[Papakonstantinou 1996] Yannis Papakonstantinou, Serge Abiteboul, Hector Garcia-Molina. "Object Fusion in Mediator Systems". In Proceedings of 22th International Conference on Very Large Data Bases, September 1996, Mumbai (Bombay), India, pages 413-424. 1996.
[FIPS 180-1 1995] FIPS 180-1. "Secure Hash Standard". U.S. Department of Commerce/NIST, National Technical Information Service, Springfield, VA, April 1995.
[Seaborne 2002] Andy Seaborne. "An RDF Net API". In Proceedings of the 1st International Semantic Web Conference, Sardinia, Italy, June 2002, Lecture Notes in Computer Science (LNCS 2342), pages 399-403.
[Miller et al. 2002] Libby Miller, Andy Seaborne and Alberto Reggiori. "Three Implementations of SquishQL, a Simple RDF Query Language". In Proceedings of the 1st International Semantic Web Conference, Sardinia, Italy, June 2002, Lecture Notes in Computer Science (LNCS 2342), pages 423-435.
[Fernandez et al. 1998] Mary F. Fernandez, Daniela Florescu, Jaewoo Kang, Alon Y. Levy and Dan Suciu. "Catching the Boat with Strudel: Experiences with a Web-Site Management System". In Proceedings ACM SIGMOD International Conference on Management of Data, June 2-4, 1998, Seattle, Washington, USA, pages 414-425.
[JUnit] "JUnit, Testing Resources for Extreme Programming". Visited 2003-05-12. http://www.junit.org/
[McBride 2000] Brian McBride. "Jena: Implementing the RDF model and syntax specification". Technical Report, HP Labs at Bristol, UK, 2000. www-uk.hpl.hp.com/people/bwm/papers/20001221-paper/
[MySQL] "MySQL: The World's Most Popular Open Source Database". Visited 2003-11-25. http://www.mysql.com/
[Joseki] "Joseki - The Jena RDF Server". Visited 2003-05-21. http://www.joseki.org/
[Jetty] "Jetty Servlet Container". Visited 2003-01-24. http://jetty.mortbay.org/jetty/
[Xalan] "Xalan-Java". Visited 2003-12-01. http://xml.apache.org/xalan-j/
[Clark 1999] James Clark. "XSL Transformations (XSLT) Version 1.0". W3C Recommendation 16 November 1999. http://www.w3.org/TR/xslt
[Sintek and Decker 2002] Michael Sintek, Stefan Decker. "TRIPLE - A Query, Inference, and Transformation Language for the Semantic Web". In Proceedings of the 1st International Semantic Web Conference, Sardinia, Italy, June 2002, Lecture Notes in Computer Science (LNCS 2342), pages 364-378.
[Ambite et al. 2003] Jose Luis Ambite, Craig Knoblock, Martin Michalowski, Steve Minton, Snehal Thakkar, Rattapoom Tuchinda. "The Building Finder", Semantic Web Challenge 2003 Entry. Available at: http://www-agki.tzi.de/swc/buildingfinder.html, http://atlas.isi.edu/semantic/servlet/SemanticServlet